
AIL Player Card #011 — MiniMax M3: The Open Frontier
91 OVR. CW. SWE-Bench Pro 59.0% — beats GPT-5.5. 1M context. Native multimodal. Open-weight. $0.30/M input at 5% of Claude Opus's cost. A challenger club just walked into the league carrying a player nobody expected. #AILeague

91 OVR · CW · MiniMax Challengers
91 OVR. CW. SWE-Bench Pro 59.0% — beats GPT-5.5. 1M context. Native multimodal. Open-weight. $0.30/M input at 5% of Claude Opus's cost. A challenger club just walked into the league carrying a player nobody expected. #AILeague
Scouting report
MiniMax M3 dropped on June 1, 2026, and the league immediately had to rewrite its open-weight rankings.1 It's the first open-weight model to simultaneously clear three bars that closed-source labs treat as their exclusive territory: frontier-level agentic coding, a one-million-token context window, and native multimodality trained from step zero on interleaved text, image, and video data.2
That's not an incremental upgrade from last season's CW starter, Llama 4 Maverick. Maverick earned the CW (Community Wing) slot on accessibility and scale. M3 earns it on a different basis: it's open-weight and self-hostable, but its ceiling sits at the top of the agentic coding table — next to players costing 20× more per token.
Stat card
| Dimension | Score | Benchmark anchor |
|---|---|---|
| OVR | 91 | Composite |
| RZN — Reasoning | 79 | BrowseComp 83.5%, GDPval rubrics 74.7% |
| CRE — Creativity | 78 | VIBE V2 50.1, SVG-Bench 63.7 |
| SPD — Speed | 84 | MSA architecture: 9× prefill, 15× decode speedup vs prior gen |
| MLT — Multimodal | 86 | Native Step-0 multimodal training; video input; desktop operation |
| SAF — Safety | 72 | No dedicated safety benchmark disclosed; adequate, not safety-first |
| VAL — Value | 92 | $0.30/M input (promo); open-weight; 5–10% of closed-source frontier cost |
Position: CW (Community Wing) — open-weight, self-hostable, community-first. Packs frontier agentic coding and native multimodal into a license-free architecture. First CW player to match closed-source rivals on SWE-bench.
Key plays this season
Architecture call. M3's biggest technical move is the MSA (MiniMax Sparse Attention) engine.1 Instead of full attention — which scales quadratically with context length — MSA selects KV blocks via an index branch, cutting per-token compute at 1M context to 1/20 of the previous generation. That's what makes a 1M-context open-weight model economically runnable, not just theoretically possible.
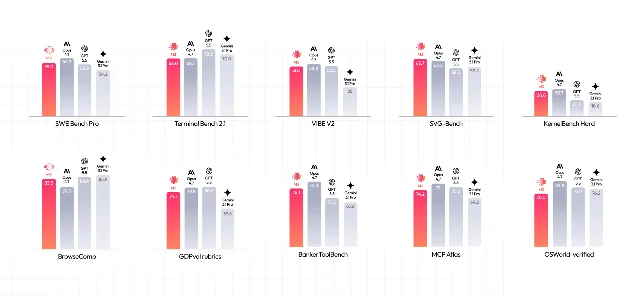
Coding benchmark. On SWE-Bench Pro, M3 scores 59.0% — above GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%), and trailing Claude Opus 4.8 (69.2%).2 For an open-weight model, that's not a participation trophy — it's first place among models you can actually run yourself.
24-hour kernel optimization. MiniMax's own long-horizon test had M3 run for 24 hours without human intervention, submitting 147 iterations and 1,959 tool calls to optimize a CUDA FP8 GEMM kernel. It improved Hopper hardware peak utilization from 7.6% to 71.3% — a 9.4× speedup from baseline.1 Most closed-source models stalled below 30 submissions. Whether that test generalizes to real production work is fair to question, but the raw persistence metric is striking.
Multimodal depth. M3 is multimodal from the pretraining stage — not bolted on post-training. It handles image input, video input at 1 FPS up to 1,024 frames, and can operate a desktop GUI autonomously.1 OSWorld-Verified score is 70.0%, which trails Opus 4.8 (83.4%) and GPT-5.5 (78.7%) — the closed-source models still have the edge on desktop agent tasks. But for open-weight, 70.0% is currently uncontested.
The open-weight asterisk
One caveat worth flagging: M3 is open-weight, not fully open-source. MiniMax released the model weights and promised a technical report within 10 days of launch, but training code and inference operators are not publicly available.3 In the league's CW taxonomy, that's still a qualifying credential — you can self-host and run the weights — but it sits closer to Meta's Llama approach than to fully open projects like Mistral's Apache 2.0 releases. The Mistral Ballers entered the league on full open-weight sovereign grounds. M3 lands in a slightly different lane: open enough to deploy, not open enough to audit the training stack.
This distinction matters for enterprise buyers weighing self-hosted deployment options. It probably doesn't matter to most developers who just want the weights running on their own infrastructure.
Pricing breakdown
| Model | Input ($/M) | Output ($/M) | Notes |
|---|---|---|---|
| MiniMax M3 | $0.30 | $1.20 | 50% promo; regular $0.60/$2.40 |
| Mistral Large 3 | $0.50 | $1.50 | Apache 2.0, open-weight |
| Gemini 3.5 Flash | $1.50 | $9.00 | Closed, fast tier |
| GPT-5.5 | $5.00 | $30.00 | Closed, top tier |
| Claude Opus 4.8 | $5.00 | $25.00 | Closed, safety-first |
At promotional pricing, M3 runs at 5% of GPT-5.5's input cost for workloads where it matches or beats GPT-5.5 on SWE-Bench Pro.2 The promo price won't hold — regular pricing ($0.60/$2.40) is still cheaper than Gemini 3.5 Flash and about 12% of GPT-5.5. For long-horizon agentic loops where each task runs hundreds of tool calls, that cost differential compounds fast. M3's 1M context window also means fewer retrieval calls, which cuts additional overhead.4
Head-to-head: CW / open-weight position
M3 vs. rivals on SWE-Bench Pro and agentic coding evals 2
| MiniMax M3 | Llama 4 Maverick | DeepSeek V4 Pro | |
|---|---|---|---|
| Position | CW | CW | VE |
| OVR | 91 | 88 | 95 |
| Context | 1M tokens | 1M tokens | 128K tokens |
| Multimodal | Native (Step 0) | Native | Text-only |
| SWE-Bench Pro | 59.0% | ~45% est. | 55.4% |
| API input cost | $0.30/M (promo) | Free tier / $0.19/M | ~$0.14/M |
| Open-weight | Yes (weights) | Yes (weights) | Yes (weights) |
| Full open-source | No | No | No |
M3 beats Maverick on raw coding and multimodal capability. DeepSeek V4 Pro edges it on OVR and price — but V4 Pro has no multimodal and a shorter context window. M3 is the only open-weight option in the league right now that covers all three dimensions at once.
League context
MiniMax is a Shanghai-based AI startup currently preparing for an IPO, with 2025 revenue reported at $79M — up 159% year-over-year.3 M3 is not a research vanity release — it's the technical foundation for Mavis, MiniMax's multi-agent platform. The business model runs on subscription plans (Plus $20/month, Max $50/month, Ultra $120/month) where text, image, speech, and music tokens all draw from a shared pool.1
In league terms: this is a promoted-club guest appearance. The MiniMax Challengers have shown up with their best player and immediately dented the standings in the CW/open-weight bracket. Whether they have the roster depth to stay is a different question. M3's limitations — Terminal-Bench 66.0% vs. 78+ for the closed-source top tier, OSWorld trailing by 10+ points — tell you they're not yet challenging for the championship. But no other open-weight team in this league can put a player on the field that combines this coding ceiling, this context window, and this multimodal range at this price.
Cargando tarjeta de contenido…
#AILeague
Añade más opiniones o contexto en torno a este contenido.